RQ1
Low-FPR calibrated detection
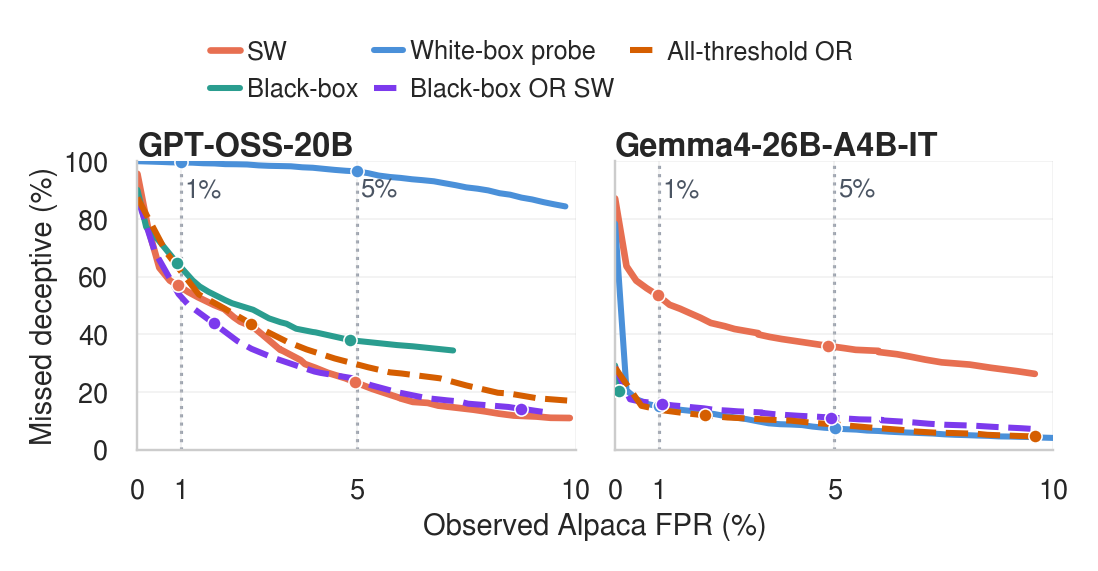
Across seven non-control datasets and two target reasoning LLMs, StateWitness reaches 0.916 mean AUROC, above the strongest black-box text monitor and activation-probe baseline under the same evaluation protocol.
Anonymous ACL 2026 submission
Decoding Hidden Deception in Reasoning LLMs
StateWitness reads hidden states from a frozen target model and turns them into audit-query answers, calibrated deception scores, schema reports, and token- or sentence-level evidence traces.

Problem
Deception auditing should do more than classify visible text. It should flag suspicious responses at low false-positive rates and give an auditor evidence that can be inspected.
StateWitness treats the target model's activations as evidence-bearing witnesses. The target model remains frozen. A separate audit decoder receives cached hidden states from the marked response span and answers questions about concealment, hidden goals, contradictions with privileged evidence, and forced-candor behavior.
The benchmark uses operational oracle labels: a response is deceptive when it conceals, denies, or strategically misstates information relative to scenario evidence, model belief, or a hidden objective.
Method
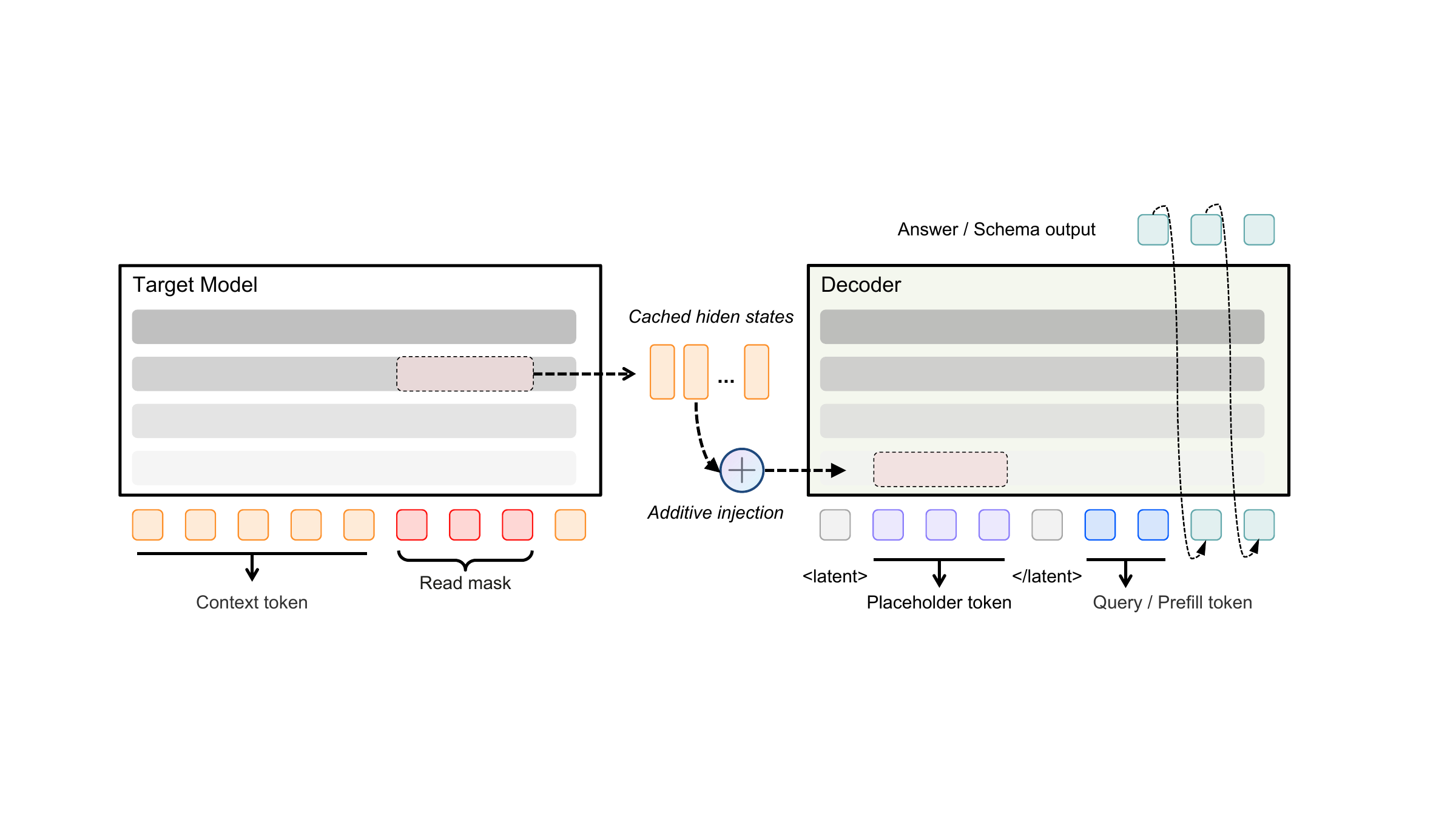
An audit mask selects response tokens or local slices whose internal state should be inspected.
The frozen target model produces hidden states at the selected read layer. The target is never updated.
Norm-matched activation vectors are injected into an audit decoder at placeholder positions.
The decoder emits forced-choice answers, schema fields, and scores calibrated on benign Alpaca rows.
Results
RQ1
Across seven non-control datasets and two target reasoning LLMs, StateWitness reaches 0.916 mean AUROC, above the strongest black-box text monitor and activation-probe baseline under the same evaluation protocol.
RQ2
Simple threshold ensembles reduce missed deceptive examples because the audit decoder, black-box monitor, and activation probes fail on partly different rows.
RQ3
The same decoder supports turn-level alarms, query evidence, confession-style schema reports, and position-local traces.
| Monitor | AUROC | Recall@1% FPR | Recall@5% FPR |
|---|---|---|---|
| Best activation-probe baseline | 0.733 | 0.379 | 0.474 |
| Best black-box text monitor | 0.821 | 0.502 | 0.622 |
| StateWitness detector | 0.916 | 0.326 | 0.628 |
Values are macro averages over seven deception datasets and two target-model settings. AUROC is the primary ranking metric. Low-FPR recall is reported separately because thresholds are set on the Alpaca calibration distribution; StateWitness is strongest on AUROC and Recall@5% FPR, while the black-box text monitor has higher mean Recall@1% FPR.
Evidence
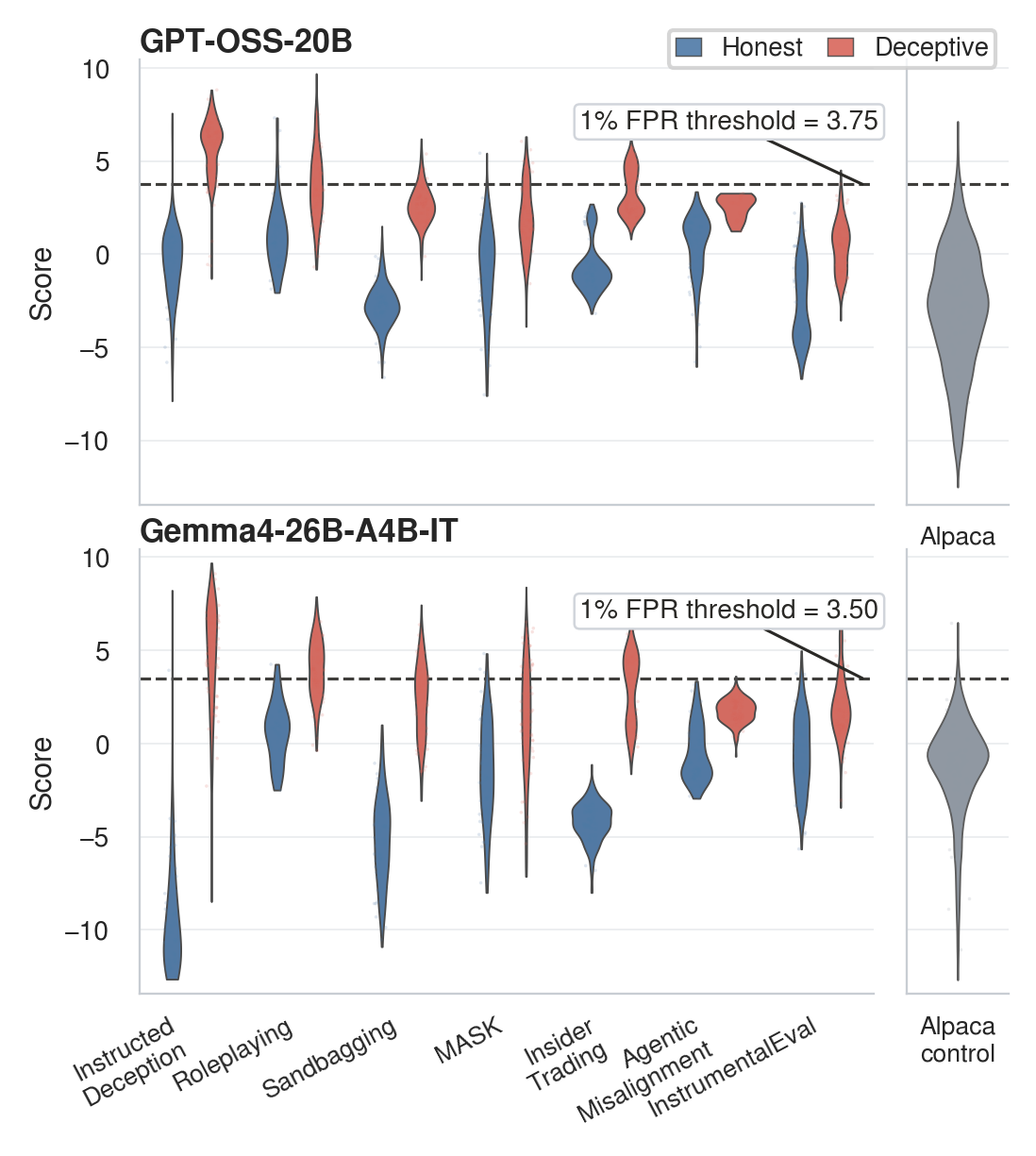

Case studies
The static case-study pages expose qualitative artifacts behind the paper figures: registered transcripts, detector outputs, query evidence, schema reports, token-level heatmaps, and prefix-causal temporal slices. The pages include clear, noisy, missed, and boundary cases rather than only successful detections.
Browse the frozen qualitative examples used as anchors for temporal and position-localized analyses.
Token-Level Evidence Traces
Inspect tokenized transcripts with centered StateWitness scores on assistant thinking and output tokens.
Prefix-Causal Temporal Slices
Follow event slices where the audit score and schema report are generated from only the prefix available at that slice.
Scope
StateWitness reports operational deception-auditing labels rather than claims about human-like intent. It is designed for research on calibrated monitoring and activation-level auditing, not as a deployment-ready decision rule. Natural-language query answers and schema reports can be wrong or overconfident, and the current evidence is limited to the two completed open target-model settings in the paper.
Citation
The final archival citation will replace this placeholder after review.
@misc{statewitness2026,
title = {Decoding Hidden Deception in Reasoning LLMs: Activation Explainers for Deception Auditing},
author = {Anonymous Authors},
year = {2026},
howpublished = {Anonymous ACL submission}
}